home..

숙명여대 1회 빅데이터 활용 해커톤 Review
July 2024 (776 Words, 5 Minutes)
프로젝트 개요 및 주제 선정 이유
-
빅데이터가 유의미하게 작용하는 분야가 무엇일지 생각해보면서, 콘텐츠 사업, 그 중 OTT 분야가 데이터 분석을 통해 얻을 수 있는 인사이트가 있을 것이라고 생각했다. 상영한 영화의 흥행 성적을 통해 OTT 에서의 흥행을 예측하는 것이 초기 목표였다.
- 따라서 우리 팀은 넷플릭스 Product팀이라는 설정 하에, OTT 시장에서의 효과적인 콘텐츠 투자 전략을 도출하기 위한 가설 설정 “ 분기7 8 9월에 범죄 액션 관련 장르의 영화를 제안하면 넷플릭스에서 한국인 20대를 타겟으로 새로운 파이프라인을 통해 매출과 사용자 수를 높일 수 있다” 를 증명하기 위해 분석을 진행했다.
- 특히 한국 영화의 OTT 콘텐츠화 과정에서 최적의 투자 방향을 제시하는 것을 목표로 했다.
📊 데이터 수집 및 분석 과정
1️⃣ 데이터 수집
프로젝트를 위해 두 가지 주요 데이터를 활용했다:
🎬 문화 빅데이터 플랫폼 ‘KOBIS 박스오피스 영화정보’
- CGV 앱 이용자는 대부분 20대이므로, 이 데이터를 20대 타겟 분석에 활용.
- 영화별 매출액, 관객수, 스크린수 등의 정보 수집
📺 넷플릭스 ‘Top 10 movies in South Korea’ 데이터
- 일주일 단위의 넷플릭스 영화 상위 10개 데이터를 수집하여 넷플릭스에서의 흥행 정보를 제공하는 핵심 데이터로 활용
2️⃣ 데이터 전처리 및 분석 방법
🔑 핵심 변수 : 총 스크린 수, 매출액, 관객수, 골든에그지수
📊 분석 모델 적용
- 랜덤 포레스트 회귀 모델 활용:
- feature importance 활용 : 영화 평점(Rate)을 Target 변수로 설정하여 예측 모델 구축
- 영화 매출, 관객 수, Golden Egg Index 등과의 상관관계 분석
- 넷플릭스 Top 10 데이터 분석
- 탑텐에 오래 유지된 영화 분석 → 흥행 패턴 파악
- 구글 트렌드 활용하여 개봉일 전후 검색 트렌드 분석
- 시각화 작업
- Golden Egg Index, 매출, 관객 수 간의 관계 그래프 생성
- Top 10 영화 지속 기간 vs 검색량 비교
3️⃣ 주요 분석 결과
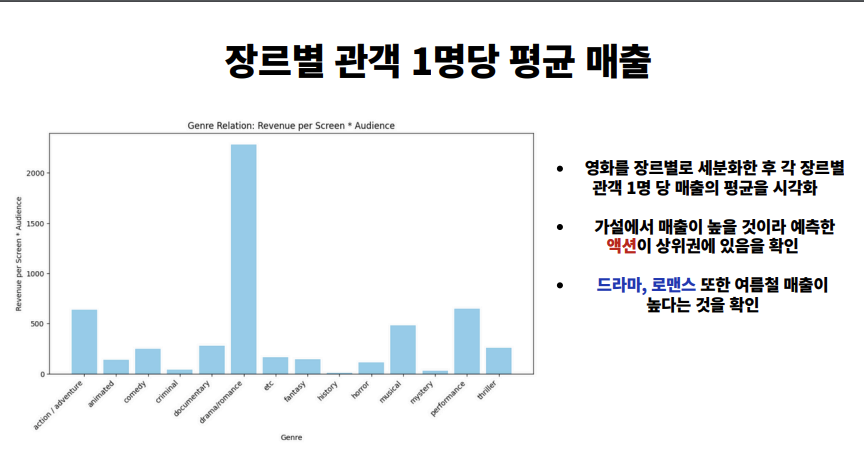
- 🎭 장르별 매출 분석
- ✅ 액션/범죄 장르가 상위권 기록
- ✅ 예상 외로 드라마, 로맨스도 여름철 높은 매출 확인
-
🔝 Top-10 순위 분석
-
✅초반 검색량이 급증하는 영화보다 일정한 관심을 유지하는 영화가 장기 흥행,구글 트렌드 분석을 통해 개봉 전후 15일간의 검색량 차이 분석.
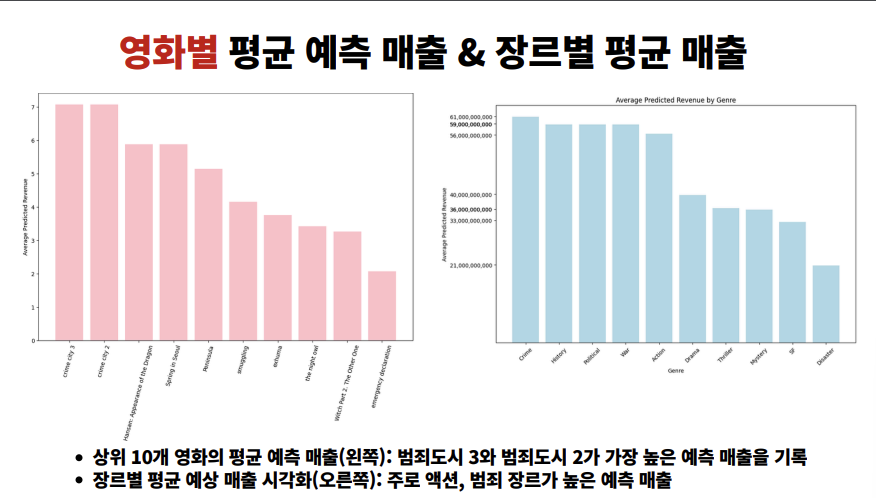
- ✅ 범죄도시 3와 범죄도시 2가 가장 높은 예측 매출 기록
- ✅ 액션/범죄, 드라마, 코미디 장르가 각각 2번씩 상위권에 등장
-
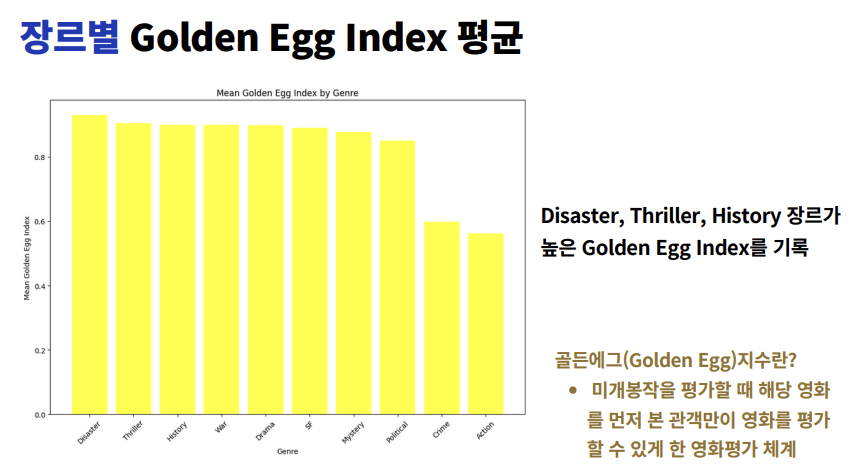
- 🍳 Golden Egg Index 분석
- ✅ Disaster, Thriller, History 장르에서 높은 지수 기록
-
회귀 모델을 통한 인사이트
- 관객 수와 Golden Egg Index의 상관관계가 낮음 (매출이 높다고 에그지수가 높진 않음)
데이터 분석에서의 어려움과 해결 방법
넷플릭스 데이터 정리 문제
- 예측 분석을 위해서는 가장 중요하게도, 큰 데이터 확보가 우선이었다. 우리는 주제를 정하자마자 넷플릭스에서 TOP 100 (한국) 정도는 쉽게 구할 줄 알았지만, 어라 현재 week TOP 10만 그것도 영문으로 구할 수 있었다…! 그래서 할 수 없이 몇 개는 한국영화정보 데이터셋에 있는 영화들을 넷플릭스에서 직접 검색해서 넷플릭스 데이터셋에 추가할 필요가 있었다..
- 그랬기에… 넷플릭스에 ‘없는’ 영화 표시도(^^) 필요했다. 20대 타겟 분석을 위해 중요 정보를 식별했는데, 이 과정이 정말 시간이 오래 걸렸다. 네 명이서 두 개의 데이터셋을 정리하는거 부터가 문제였던거 같다..^^;엑셀을 더 자유자재로 다룰 줄 알았다면 ‘넷플릭스 TOP 10 데이터’ 와 열들을 비교해서 필터링을 하는 작업을 단축할 수 있었을 싶다.
- 기간별 데이터 파일에서 중복된 것들을 제거하는 것도 시간이 꽤 오래 걸렸다. 왜냐!! 한글로 된 이름과 영어로 된 이름들이 있었기 때문에…. 이것은 엑셀 함수로 어떻게 할수가 없었고..GPT 를 맹신할수도 없었다 ( 생각보다 한국 OTT는 해외로 번역되면서 아예 제목이 바뀌는 경우가 있었다.)
- 참고로 데이터 개수는 4000개였다…
데이터 전처리 문제
- 그 놈의 OTT 제목 문제 때문에 COLAB 에서 완전히 전처리를 할 수 가 없었다.
- 또한 열심히 크롤링을 했지만… 필요 없는 요소들은 결국 삭제 (확장판, 스틸컷, 재개봉작)
- 평점 데이터를 대체한 Golden Egg (에그지수) 의 ? 및 N/A 값에서, ?는 검색해서 채워넣고, N/A는 0으로 대체했다. (차라리 그냥 널값으로 채워도 괜찮았을텐데…)
심사평 및 광탈
-
넷플릭스 내부 데이터에 대한 접근이 제한되었기 때문에 , 시청자 행동 패턴 데이터가 부재했다. 하필 우리가 발표하기 전 팀이 감정 분석, 댓글 분석같은 것을 진행하였기 때문에 우리의 정성적 평가 부족은 더욱 티가 났다.
- 배우의 인지도, 마케팅 비용 등 추가 변수 고려가 필요하다는 평가를 받았다.
- 또한 ( 해커톤에서 왜이렇게 바라는게 많았는지 잘 모르겠지만) 심사위원 측에서 글로벌 시장 반응 데이터가 부족했다는 평가도 받았다. 데이터가 몇 개인지 물어보시고, 4000개라고 하자 데이터의 개수보다 종류를 좀 더 많이 모으는게 낫다고 하셨다.
결국 상을 하나도 못 받고 광탈하였다.
느낀 점
- 너무 많은 것을 고려하고 싶지 않아서 넷플릭스와 영화 상영 ‘성적’ 간의 관계에 집중을 했는데… 여전히 신경쓸게 많아서 답답했다.
- 또한 교수님들이 피드백하실 때 … 저희는 매출과 장르의 관계만 파악한 게 아니라, 이용자별 단위 매출과 장르를 비교하고, 에그지수, 관객 수 , 스크린 수 등 여러 요인을 파악하여 공통되는 것 만을 바탕으로 결론을 냈는데 이 부분에 집중을 안 하셔서 너무나 아쉬워요!!!!! 부연설명을 했었어야 했는데 그저 넘긴 점이 속상하다!!!!!!!!!!!!!!!!!!!!!!!!🥹
- 문제상황을 인지하고 분석 과정을 진행해나갔는데 점점 시간이 갈수록 문제상황과 동떨어지는 상황이 발생했다. 또한 ‘의미 있는 결론’ 을 도출하는 것이 굉장히 헷갈렸음. 결말과 가설을 잇는 연습이 필요한 것 같다.
- 데이터 열 title.. 계속 한 글자씩 틀려서 오류가 무한대로 났다. 컬럼 라벨링부터 확실히 하기
향후 연구 방향
- 마케팅 비용 /배우 인지도/제작사 규모/IP 활용 여부를 모두 고려할 것이다.
- 국가별 선호도 차이를 분석하고, 소득수준에 따른 콘텐츠 선호도 연구를 했을 것이다.
-
프레임워크: 문제 제안 이유, 데이터, 가설 설정, 가설 검증, 결론
을 그대로 다음 해커톤에 적용해야 겠다!
Special Thanks to
-
박성현
- 역할: 팀원 및 조장
- 학과/전공: 컴퓨터과학과
-
윤나린
- 역할: 데이터 전처리 및 수집 담당
- 학과/전공: 컴퓨터과학과
-
윤서빈
- 역할: 데이터 분석 담당
- 학과/전공: 데이터사이언스 전공
-
신진수 멘토님
- 역할: 멘토
- Krafton 데이터사이언티스트
Post
- 구글 트렌드 데이터 크롤링 방법 :