핸즈온 머신러닝 2.1~2.4
March 2025 (2121 Words, 12 Minutes)
2장- 머신러닝 프로젝트 처음부터 끝까지
2.1 실제 데이터로 작업하기
• 유명한 공개 데이터 저장소
- OpenML(https://openml.org)
- 캐글(https://kaggle.com/datasets)
- PapersWithCode(https://paperswithcode.com/datasets)
- UC 어바인 머신러닝 저장소 (https://archive.ics.uci.edu/ml)
- 아마존 AWS 데이터셋(https://registry.opendata.aws)
- 텐서플로 데이터셋(https://tensorflow.org/datasets) 메타 포털(공개 데이터 저장소가 나열되어 있는 페이지) 데이터 포털(https://dataportals.org)
- 오픈 데이터 모니터(https://opendatamonitor.eu) 인기 있는 공개 데이터 저장소가 나열되어 있는 다른 페이지 위키백과 머신러닝 데이터셋 목록 (https://homl.info/9) Quora(https://homl.info/10) 데이터셋 서브레딧 subreddit (https://www.reddit.com/r/datasets)
2.2 큰 그림 보기
- 활용 데이터: 캘리포니아의 블록 그룹마다 인구, 중간 소득, 중간 주택 가격 등을 담고 있다.
- 이 데이터로 모델을 학습시켜서 다른 측정 데이터가 주어졌을 때 구역의 중간 주택 가격을 예측.
2.2.1 문제 정의
머신러닝 프로젝트 접근 가이드
-
비즈니스 목적 파악
비즈니스의 목적이 정확히 무엇인지 이해하는 것이 첫 번째 단계이다.모델 자체가 아닌 모델을 통해 얻고자 하는 비즈니스 가치를 파악해야 한다. 목적 이해는 문제 구성, 알고리즘 선택, 성능 지표 선정, 모델 튜닝 노력 결정에 영향을 미친다.
- 예시: 구역 중간 주택 가격 예측 모델은 투자 결정을 위한 입력 신호로 사용된다.
-
데이터 파이프라인 이해
데이터 파이프라인은 연속된 데이터 처리 컴포넌트들의 집합이다.컴포넌트들은 비동기적으로 작동하며 독립적이다.장점:시스템 이해도 향상,팀별 집중 가능,시스템 견고성 증가 단점:모니터링 부재 시 고장 인지 지연,오래된 데이터 사용 시 전체 성능 저하
-
현재 솔루션 분석
기존 솔루션은 참고 성능 지표와 문제 해결 방향에 대한 통찰을 제공한다.
- 예시: 현재는 전문가가 복잡한 규칙으로 수동 추정하여 비용과 시간이 많으며 정확도가 낮다(30% 이상 오차). 인구 조사 데이터셋은 중간 주택 가격 예측에 적합한 데이터로 판단된다.
-
학습 방식 결정
지도 학습: 레이블된 훈련 샘플(구역 데이터와 중간 주택 가격)이 있어 적합하다.
회귀 문제: 값(중간 주택 가격)을 예측하는 회귀 문제이다.
다중 회귀: 여러 특성(인구, 중간 소득 등)을 사용한다.
단변량 회귀: 각 구역당 하나의 값만 예측한다. 배치 학습: 데이터 크기가 적당하고 연속적 데이터 흐름이 없어 적합하다.
-
대규모 데이터 처리1
2.2.2 성능 지표 선택
머신러닝 모델의 성능을 평가하기 위해 적절한 측정 지표(metric) 를 선택하는 것이 중요하다. 특히 회귀 문제(regression) 에서는 평균 제곱근 오차(RMSE, Root Mean Square Error) 가 일반적으로 사용된다. RMSE는 오차가 커질수록 값이 더 커지므로, 예측 성능이 얼마나 정확한지 직관적으로 이해 가능
RMSE는 다음과 같이 계산된다.
$ RMSE(X, h) = \sqrt{\frac{1}{m} \sum_{i=1}^{m} (h(x^{(i)}) - y^{(i)})^2} $
- $m$: 데이터셋의 샘플 수
- $x^{(i)}$: $i$번째 샘플의 특성 벡터
- $y^{(i)}$: $i$번째 샘플의 실제 값 (타겟 값)
- $h(x^{(i)})$: 모델이 예측한 값 (가설 함수)
RMSE는 오차의 제곱을 평균내고 제곱근을 취하므로, 오차의 크기가 클수록 더 큰 영향을 미친다. 따라서 큰 오차를 더 중요하게 다루고 싶을 때 RMSE를 사용하면 유용하다.
평균 절대 오차 (MAE)
이상치(outlier)가 많을 경우 평균 절대 오차(MAE, Mean Absolute Error) 를 사용하는 것이 더 적절할 수 있다.
MAE는 다음과 같이 계산된다.
$
[
MAE(X, h) = \frac{1}{m} \sum_{i=1}^{m} | h(x^{(i)}) - y^{(i)} |
]
$
차이점: RMSE vs MAE RMSE는 이상치가 있는 경우 영향을 크게 받고, MAE는 이상치 영향을 상대적으로 덜 받는다.이러한 특성 때문에 RMSE는 종 모양 분포의 양 끝단처럼 이상치가 매우 드문 일반적인 데이터 분포에서 자주 사용되지만, 이상치가 많다면 MAE가 더 적절할 수 있다.
2.2.3 가정 검사
- 팀원들과 지금까지 만든 가정을 나열하고 검사해보기. 심각한 문제를 일찍 발견할 수 있기에 꼭 해보자.문제를 회귀or 분류 등 어떤 solution 으로 해결을 할지 확인을 꼭 해야 한다.
2.3 데이터 가져오기
02_end_to_end_machine_learning_project.ipynb
# 데이터를 추출하고 로드하는 함수
from pathlib import Path
import pandas as pd
import tarfile
import urllib.request
def load_housing_data():
tarball_path = Path("datasets/housing.tgz")
if not tarball_path.is_file():
Path("datasets").mkdir(parents=True, exist_ok=True)
url = "https://github.com/ageron/data/raw/main/housing.tgz"
urllib.request.urlretrieve(url, tarball_path)
with tarfile.open(tarball_path) as housing_tarball:
housing_tarball.extractall(path="datasets")
return pd.read_csv(Path("datasets/housing/housing.csv"))
housing = load_housing_data()
load_housing_data() 함수를 호출하면 datasets/housing.tgz 파일을 찾는다.
2.3.6 데이터 구조 훑어보기
head() –> 각 행은 하나의 구역을 나타냅니다. 특성은 longitude, latitude, housing*median_age. total_rooms. total_bedrooms, population. households, median_income. median_house_value, ocean_proximity 등 10개
info() -> 전체 행 수, 각 특성의 데이터 타입과 널이 아닌 값의 개수 확인 . 20,640개의 샘플,ocean_proximity 필드만 빼고 모든 특성이 숫자형.
describe() -> 숫자형 특성의 요약 정보, std 행은 값이 퍼져있는 정도를 측정하는 표준 편차를 나타낸다.
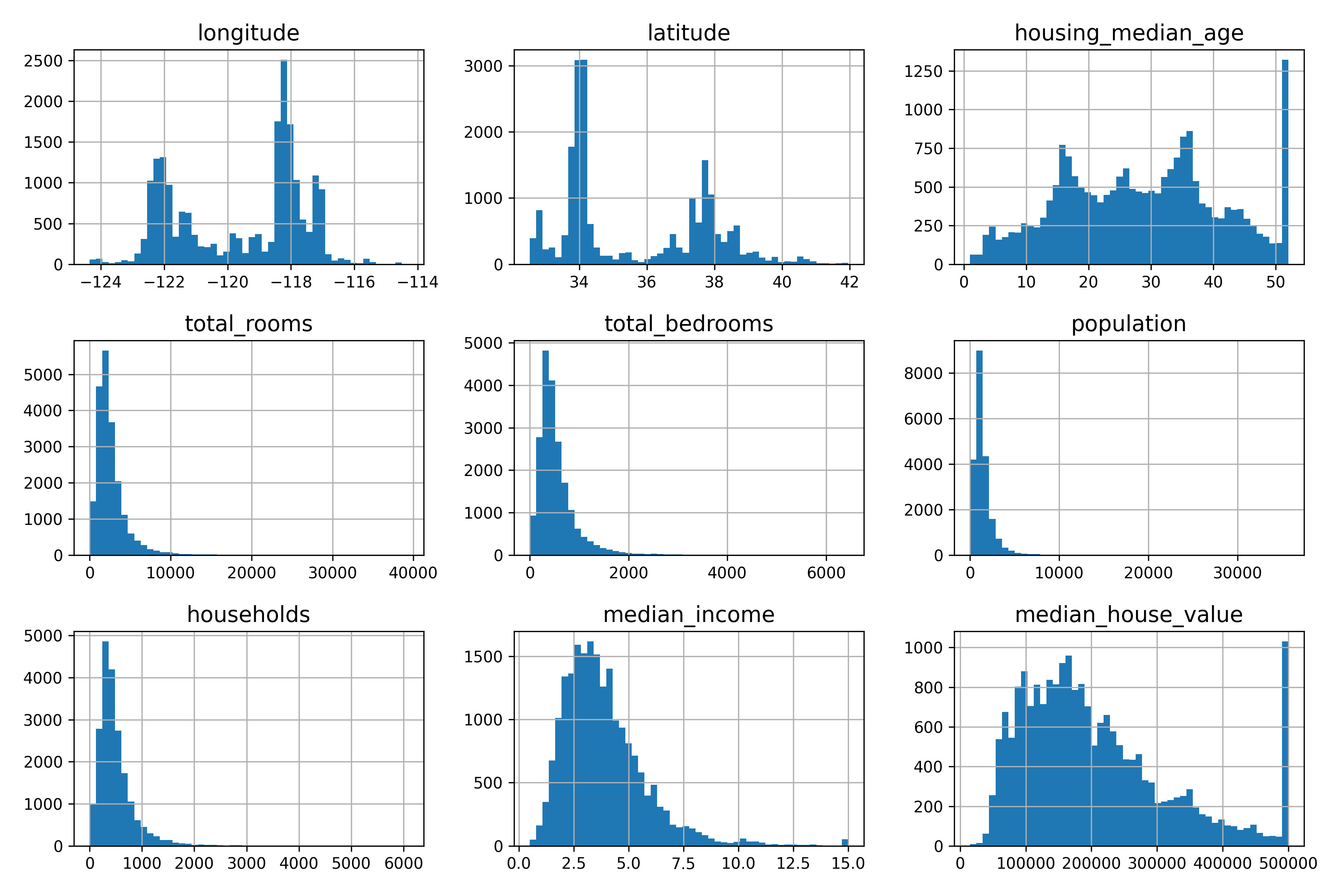
모든 숫자형 특성에 대한 히스토그램.중간 소득은 달러 단위가 아니라 숫자로 변환되어 있음을 확인 가능하다.또한 중간 주택 연도와 중간 주택 가격의 최댓값과 최솟값이 제한되어있다. 이를 해결하기 위해 한계값 데이터의 정확한 레이블을 확보하고, 훈련 세트에서 이런 구역을 제거해야 한다. 마지막으로 일부 특성 값이 다른 특성보다 훨씬 크거나 작은데, ml 에서는 스케일이 다르면 학습이 어려울 수 있다. 따라서 특성 스케일링을 통해 표준화 or 정규화를 사용해야 한다.
- 대부분의 histogram 에서 오른쪽 꼬리가 더 긴데, 일부 ml 알고리즘은 정규분포가 아닌 경우 패턴을 찾기 어렵다. 따라서 데이터 변환을 통해 더 정규분포에 가깝도록 조정해야 한다. 3
2.3.7 테스트 세트 만들기
머신러닝 모델을 평가하기 위해 일부 데이터를 미리 떼어 놓는 것(테스트 세트 생성) 은 매우 중요하다.
하지만 처음부터 데이터를 나누는 것이 어색하게 느껴질 수도 있다.
“데이터를 충분히 분석하고 나서 테스트 세트를 만들어야 하는 것 아닌가?”
사실 그렇지 않다!
우리 뇌는 패턴 감지에 매우 능하지만, 과대적합되기 쉽다. 즉, 테스트 데이터를 미리 보면, 우리가 무의식적으로 특정 패턴을 보고 모델을 선택할 가능성이 높다. 이러한 문제를 데이터 스누핑 편향(Data Snooping Bias) 이라고 한다.
✅ 테스트 세트 생성 방법
1️. 랜덤 샘플링 기반 테스트 세트 생성
테스트 세트를 생성하는 가장 간단한 방법은랜덤으로 데이터를 분할하는 것이다.
import numpy as np
def shuffle_and_split_data(data, test_ratio):
shuffled_indices = np.random.permutation(len(data)) # 데이터 랜덤 섞기
test_set_size = int(len(data) \* test_ratio) # 테스트 세트 크기 계산
test_indices = shuffled_indices[:test_set_size] # 앞부분을 테스트 세트로
train_indices = shuffled_indices[test_set_size:] # 나머지를 훈련 세트로
return data.iloc[train_indices], data.iloc[test_indices]
# 실행 예시
train_set, test_set = shuffle_and_split_data(housing, 0.2)
print(len(train_set)) # 80% 훈련 세트
print(len(test_set)) # 20% 테스트 세트
/*
프로그램을 다시 실행하면 다른 테스트 세트가 생성될 수 있고, 이를 방지하지 않으면 모델이 결국 전체 데이터를 학습하게 되는 상황이 발생할 수도 있다.
*/
-
난수 고정 항상 같은 테스트 세트를 생성하려면 난수 생성기의 초기값(seed)을 고정하면 된다. np.random.seed(42)
데이터셋이 업데이트되면 기존 샘플이 테스트 세트에서 사라질 수 있다.이 경우, 식별자를 기반으로 테스트 세트를 고정하는 방법을 고려해야 한다.
✅ 식별자 기반 테스트 세트 생성:샘플의 고유한 식별자(ID)를 기준으로 테스트 세트를 고정하면, 데이터가 변경되어도 일관성을 유지할 수 있다.
from zlib import crc32
def is_id_in_test_set(identifier, test_ratio):
return crc32(np.int64(identifier)) < test_ratio * 2**32
def split_data_with_id_hash(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: is_id_in_test_set(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set]
- 데이터에 식별자 컬럼(ID)이 있는 경우 → 해당 컬럼을 사용
- 식별자가 없을 경우 → 데이터의 행 인덱스를 ID로 활용
- housing_with_id = housing.reset_index() # 인덱스를 ID로 사용, train_set, test_set = split_data_with_id_hash(housing_with_id, 0.2, “index”)
- 또는, 위도(longitude)와 경도(latitude)를 조합하여 ID를 생성할 수도 있다.
✅ 사이킷런을 활용한 간단한 방법 - 사이킷런(Scikit-learn)의 train_test_split() 함수를 사용하면 더욱 간편하게 테스트 세트를 만들 수 있다.
- random_state=42 를 설정하면 매번 같은 테스트 세트가 생성되고, 여러 개의 데이터셋을 동일한 인덱스로 나눌 수 있지만 단순 랜덤 샘플링은 특정 그룹이 과소/ 과대 대표될 가능성이 있음. 따라서 stratified sampling 사용
✅ 계층적 샘플링 (Stratified Sampling) 랜덤 샘플링은 데이터셋이 충분히 크다면 괜찮지만, 데이터가 적으면 특정 집단이 과소/과대 대표될 위험이 있다.
- 계층 특성(중간 소득) 만들기: 중간 소득은 연속형 숫자이므로, 이를 카테고리 변수로 변환하여 계층을 나눌 수 있다.
housing["income_cat"] = pd.cut(housing["median_income"],
bins=[0., 1.5, 3.0, 4.5, 6., np.inf],
labels=[1, 2, 3, 4, 5])
- 계층적 샘플링을 적용하여 test set 생성: 사이킷런의 StratifiedShuffleSplit을 활용하면 계층 비율을 유지하면서 샘플링할 수 있다.계층적 샘플링을 사용하면, 테스트 세트의 소득 카테고리 비율이 전체 데이터셋과 거의 일치한다.
from sklearn.model_selection import StratifiedShuffleSplit
splitter = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in splitter.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
#또는, 더 간단하게 train_test_split() 함수에서 계층적 샘플링 적용 가능!
train_set, test_set = train_test_split(
housing, test_size=0.2, stratify=housing["income_cat"], random_state=42)
2.4 데이터 이해를 위한 탐색과 시각화
탐색 전에 테스트 세트를 분리하고 원본 데이터 보존을 위해 복사본을 생성해야 한다. 테스트 세트를 떼어놓았는지 확인하고 훈련 세트에 대해서만 탐색을 한다.
2.4.1 지리적 데이터 시각화하기
- 모든 구역을 기본 산점도로 만들어 데이터를 시각화
- 밀집도를 강조한 산점도 : alpha=0.2 (투명도로 밀집도 표현)
- 다차원 정보를 표현한 산점도 - 예시에서 주택 가격은 해안가 근접성 및 인구 밀도와 높은 관련성을 보임
housing.plot(kind="scatter",
x="longitude",
y="latitude",
grid=True,
s=housing["population"]/100, # 원 크기로 인구 표현
label="인구",
c="median_house_value", # 색상으로 주택 가격 표현
cmap="jet",
colorbar=True,
legend=True,
figsize=(10, 7))
cax = plt.gcf().get_axes()[1]
cax.set_ylabel("중간 주택 가격")
plt.xlabel("경도")
plt.ylabel("위도")
plt.show()
2.4.2 상관관계 조사하기
- correlation 범위 : -1부터 1, 1에 가까우면 강한 양의 상관관계.
corr_matrix = housing.corr(numeric_only=True)
corr_matrix["median_house_value"].sort_values(ascending=False)
- 특성 사이 상관관계 확인하는 다른 방법-산점도 행렬 : scatter_matrix 함수 사용. 결과에서 대각선 위치에는 각 변수 자신에 대한 산점도가 출력되어야 하는데, 이는 그냥 직선이므로 유용하지않음.
주요 상관관계 확대 분석하기- 중간 소득 산점도 확대
중간 소득이 중간 주택 가격과 가장 강한 상관관계(0.688)를 보임, 지리적 위치(해안가 근접성)가 주택 가격에 큰 영향을 미침.데이터에 뚜렷한 가격 한계값들이 존재:$450,000, $350,000, $280,000 등에서 수평선 패턴 발견
상관관계 해석 시 주의사항 : 상관계수는 선형적 관계만 측정함,비선형 관계는 상관계수로 파악할 수 없음. 두 특성이 완전히 독립적이지 않더라도 상관계수가 0일 수 있음, 단위 변경은 상관계수에 영향을 주지 않음 (예: 인치, 피트, 나노미터 단위의 키는 모두 상관계수 1)
2.4.3 특성 조합으로 실험하기
앞서 데이터를 탐색하고, 특성 간의 상관관계를 분석하여 유용한 정보를 얻는 방법을 살펴보았다. 머신러닝 알고리즘에 데이터를 주입하기 전에 새로운 특성을 생성하여 성능을 향상시키는 방법을 다룬다.
✅ 특성 변형 (Feature Transformation)
특정 특성의 분포가 오른쪽 꼬리가 긴 형태(skewed distribution) 를 보인다면, 데이터 변환을 통해 정규분포(종 모양) 형태로 조정하는 것이 좋다.
✔ 변환 방법 예시
- 로그 변환(Log Transformation):
log(x) - 제곱근 변환(Square Root Transformation):
sqrt(x) - Box-Cox 변환 (정규성을 강하게 만들기 위해 사용)
✅ 유용한 특성 조합 만들기
어떤 특성은 단독으로는 의미가 없지만, 다른 특성과 조합하면 더 유용할 수 있다.
- 전체 방 개수(
total_rooms) → 단독으로는 의미가 크지 않음
→ 대신 가구 수(households)와의 비율을 계산하면 유용함 - 침실 개수(
total_bedrooms) → 방 개수(total_rooms)와 비교하는 것이 더 효과적
🔹 새로운 특성 추가
housing["rooms_per_house"] = housing["total_rooms"] / housing["households"]
housing["bedrooms_ratio"] = housing["total_bedrooms"] / housing["total_rooms"]
housing["population_per_house"] = housing["population"] / housing["households"]
- 새로운 bedrooms_ratio 특성은 전체 방 개수나 침실 개수보다 중간 주택 가격과의 상관관계가 훨씬 높다.