핸즈온 머신러닝 1.4~1.6
March 2025 (2969 Words, 17 Minutes)
1.4~1.6
머신러닝 시스템의 종류
훈련 지도 방식(지도, 비지도, 준지도, 자기 지도, 강화 학습) 실시간으로 점진적인 학습을 하는지 아닌지(온라인 학습과 배치 학습) 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처 럼 훈련 데이터셋에서 패턴을 발견하여 예측 모델을 만드는지(사례 기반 학습과 모델 기반 학습)
1.4.1 훈련 지도 방식
- 지도 학습: 알고리즘에 주입하는 훈련 데이터에 레이블이라는 답 포함.
- 분류(스팸 필터 ): 많은 샘플 이메일과 클래스로 훈련된다.
- 회귀 (feature 을 이용해 중고차 가격 같은 타겟 수치를 예측하는 것.)
- 회귀 알고리즘 -> 분류에 사용 , 분류 알고리즘 -> 회귀에 사용
- = Logistic regression
- 비지도 학습: no labels
-
- 시각화 알고리즘 ( 레이블 X 대규모의 고차원 데이터를 넣으면 도식화가 가능한 표현을 만들어줌. )
- 차원 축소
- feature extraction : 차원 상관관계가 있는 여러 특성을 하나로 합치는 것.
-
- 이상치 탐지: 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제거. 시스템은 훈련하는 동안 대부분 정상 샘플을 만나 이를 인식하도록 훈련–> 새로운 데이터셋을 보고 정상인지 이상치인지 판단
- = 특이치 탐지
- 이상치 탐지: 부정 거래를 막기 위해 이상한 신용카드 거래를 감지하고, 제거. 시스템은 훈련하는 동안 대부분 정상 샘플을 만나 이를 인식하도록 훈련–> 새로운 데이터셋을 보고 정상인지 이상치인지 판단
-
- 연관 규칙 학습 (association rule learning): 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 학습.
-
- 준지도 학습: 레이블이 없는 샘플이 많고 레이블된 샘플은 적은 경우가 많아. –> 어떤 알고리즘은 레이블이 일부만 있는 데이터를 다룸. 대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 이루어져 있음.
- 자기 지도 학습: 레이블이 전혀 없는 데이터셋에서 레이블이 완전히 부여된 데이터셋 을 생성하는 것.전체 데이터셋에 레이블이 부여되고 나면 어떤 지도 학습 알
고리즘도 사용할 수 있다. 자기 지도 학습은 훈련하는 동안 레이블을 사용하기 때문에 지도 학습에 더 가깝다.
- 손상된 이미지를 복원하거나 사진에서 원치 않는 물체를 삭제 가능
- 레이블이 있는 데이터셋에서 모델을 미세 튜닝하는 것
한 작업에서 다른 작업으로 지식을 전달하는 것을 transfer learning 이라고 한다.
- 강화 학습: agent 가 environment를 관찰해서 action을 실행하고 그 결과로 reward + penalty 를 받는다. 시간이 지나면서 가장 큰 보상을 얻기 위해 정책policy 라고 부르는 최상의 전략을 스스로 학습한다. 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의한다.
- 보행 로봇을 만들기 위해 강화학습 알고리즘을 사용.
- Deepmind 의 알파고. 알파고가 게임할때 학습 기능을 끄고 그동안 학습했던 전략을 적용 –> 오프라인 학습
1.4.2 배치 학습과 온라인 학습
머신러닝 시스템을 분류하는 데 사용하는 다른 기준 : 입력 데이터의 스트림으로부터 점진적으로 학습할 수 있는지 여부
- 오프라인 학습- batch learning 에서는 시스테밍 점진적으로 학습할 수 없다. 가용한 데이터를 모두 사용해 훈련시켜야 한다. 시간과 자원을 많이 소모하므로 오프라인에서 수행된다.
- 시스템을 훈련시킨 다음 제품 시스템에 적용하면 더 이상의 학습 없이 실행된다. 즉, 학습한 것을 단지 적용만 한다.
- 모델의 성능은 시간이 지남에 따라 천천히 감소하는 경향이 있다 -> model rot / data drift 따라서 최신 데이터에서 모델을 정기적으로 재훈련해야 함. 데이터를 update 하고 시스템의 새 버전을 필요한 만큼 자주 훈련시키면 됨
- 배치 학습 시스템이 새로운 데이터셋에 대해 학습하려면 전체 데이터를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 한다. 그런 다음 이전 모델을 새 모델로 교체한다. But 전체 데이터셋을 사용해 훈련한다면 많은 컴퓨팅 자원이 필요하다. 대량의 데이터를 가지고 있는데 매일 처음부터 새 로 훈련시키도록 시스템을 자동화한다면 큰 비용이 발생할 것이다. 데이터 양이 아주 많으면 배치 학습 알고리즘을 사용하는게 불가능할 수도 있다.
- 온라인 학습(점진적 학습): 데이터를 순차적으로 한 개씩 or mini-batch 라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킨다. 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습 가능하다. 온라인 학습에서는 모델을 훈련하고 제품에 론칭한 뒤에도 새로운 데이터가 들어오면 계속 학습한다. 온라인 학습에서 가장 큰 문제점은 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 감소한다는 점. 즉 데이터 품질과 학습률에 따라서 빠르게 감소 가능.
- 극도로 빠른 변화에 적응해야 하는 시스템: 주식 시장에서 새로운 패턴을 탐지하는 시스템에 적합
- 모바일 디바이스에서 모델을 훈련할 때
out-of-core learning을 통해 온라인 학습 알고리즘을 사용하여 (컴퓨터 한 대의 메인 메모리에 들어갈 수 없는 아주 큰 데이터셋에서) 데이터 일부를 읽어들이고 훈련 단계를 수행한다.
학습률 : 온라인 학습 시스템에서 중요한 파라미터는 변화하는 데이터에 얼마나 빠르게 적응할 것인지. 학습률을 높게 하면 시스템이 데이터에 빠르게 적응하지만 예전데이터를 금방 잊어버림. 낮으면 시스템의 관성이 더 커져서 더 느리게 학습.
1.4.3 사례 기반 학습과 모델 기반 학습
머신러닝 시스템의 일반화와 분류
머신러닝 시스템은 일반화(generalization) 방식에 따라 분류될 수 있다. 대부분의 머신러닝 작업은 주어진 훈련 데이터를 학습하고, 이전에 본 적 없는 새로운 데이터에서도 좋은 예측을 만드는 것이다. 단순히 훈련 데이터에서 높은 성능을 내는 것만이 목표가 아니라, 새로운 샘플에서도 잘 작동해야 한다.
일반화를 위한 접근법은 크게 사례 기반 학습(instance-based learning) 과 모델 기반 학습(model-based learning) 으로 나뉜다.
1. 사례 기반 학습 (Instance-Based Learning)
가장 단순한 학습 방법은 기억하는 것이다. 예를 들어, 스팸 필터를 단순히 사용자가 스팸으로 지정한 메일과 동일한 메일을 스팸으로 분류하는 방식이다. 하지만 이는 최적의 방법이 아니다.
더 발전된 방법은 스팸 메일과 유사한 메일을 스팸으로 구분하는 것이다. 이를 위해 유사도(similarity) 를 측정하는 방법이 필요하다. 간단한 방법으로는 공통 단어의 개수를 세는 것이 있다. 스팸 메일과 공통 단어가 많을수록 스팸으로 분류할 가능성이 높아진다.
이러한 방식이 사례 기반 학습이다. 훈련 샘플을 기억한 후, 새로운 데이터와 학습 샘플(혹은 일부) 간의 유사도를 비교하여 일반화하는 방식이다. 예를 들어, 새로운 샘플이 가장 비슷한 샘플들과 다수 일치하는 클래스로 분류된다.
2. 모델 기반 학습 (Model-Based Learning)
사례 기반 학습과 달리, 모델을 만들어 예측에 사용하는 방법이 있다. 이를 모델 기반 학습이라고 한다.
예를 들어, 돈이 사람을 행복하게 만드는지 알아보기 위해 OECD의 Better Life Index 데이터와 1인당 GDP 데이터를 활용한다고 가정하자. 데이터를 정리해 보면 삶의 만족도는 1인당 GDP가 증가할수록 선형적으로 증가하는 경향을 보인다.
이러한 관계를 선형 모델(linear model) 을 이용해 표현할 수 있다.
삶의 만족도 공식에서 θ₀ 와 θ₁ 은 모델의 파라미터(model parameters) 이며, 모델을 훈련시키면서 최적의 값을 찾는다.
이를 위해 비용 함수(cost function) 를 최소화하는 모델을 찾아야 한다. 선형 회귀(linear regression) 알고리즘을 사용하면 주어진 데이터를 가장 잘 표현하는 최적의 모델 파라미터를 학습할 수 있다.
3. 사례 기반 학습 vs 모델 기반 학습
키프로스(Cyprus)의 1인당 GDP를 바탕으로 삶의 만족도 예측을 비교해 보자.
-
모델 기반 학습:
- 학습된 선형 모델을 사용하여 예측한다.
- 예측 값: 6.30
-
사례 기반 학습 (k-최근접 이웃, k-NN):
- GDP가 비슷한 국가들을 찾아 평균을 구한다.
- 예측 값: 6.33 (이스라엘, 리투아니아, 슬로베니아의 평균)
최근접 이웃 회귀(k-NN 회귀)는 모델 기반 학습보다 단순하지만, 더 많은 데이터를 필요로 한다. 반면, 모델 기반 학습은 일반적으로 훈련된 모델만 있으면 새로운 샘플을 쉽게 예측할 수 있다.
4. 머신러닝 프로젝트의 전형적인 과정
머신러닝 프로젝트는 다음과 같은 단계를 따른다.
- 데이터 분석: 데이터를 수집하고 패턴을 분석한다.
- 모델 선택: 데이터를 가장 잘 표현할 수 있는 모델을 선택한다.
- 모델 훈련: 훈련 데이터를 사용해 학습 알고리즘이 비용 함수 최소화를 목표로 모델 파라미터를 최적화한다.
- 모델 적용 (추론, inference): 새로운 데이터에 모델을 적용하여 예측을 수행한다.
이 과정을 통해 모델이 현실에서도 일반화되도록 만드는 것이 머신러닝의 핵심 목표이다.
1.5 머신러닝의 주요 도전 과제
1.5.1 충분하지 않은 양의 훈련 데이터
대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 함. 여전히 소규모 데이터셋이 흔하고 훈련 데이터를 추가로 모으는 것이 항상 쉽거나 저렴한 일은 아니므로 아직은 알고리즘을 무시하지 말아야 함.
1.5.2 대표성 없는 훈련 데이터
일반화 - 사례 기반 학습, 모델 기반 학습 마찬가지로 훈련 데이터가 일반화하고 싶은 새로운 사례를 잘 대표해야 함
머신러닝 모델이 일반화(generalization) 되려면, 훈련 데이터가 일반화하고자 하는 새로운 사례를 잘 대표해야 한다.
이 원칙은 사례 기반 학습(instance-based learning) 과 모델 기반 학습(model-based learning) 모두에 적용된다.
예를 들어, 앞서 사용한 1인당 GDP와 삶의 만족도 데이터를 살펴보자.
이 데이터에는 1인당 GDP가 23,500달러보다 적거나 62,500달러보다 많은 나라가 빠져 있다. 즉, 일부 국가가 제외되었으므로 데이터의 대표성이 완벽하지 않다.
이러한 훈련 데이터를 사용하면 특정 구간에서는 정확한 예측이 어렵다. 특히, 매우 가난하거나 매우 부유한 국가에서 모델의 예측이 크게 틀릴 수 있다.
샘플링 문제: 샘플링 잡음 vs 샘플링 편향
훈련 세트가 대표성을 갖는 것이 중요하지만, 대표성이 부족한 데이터는 샘플링 잡음(sampling noise) 또는 샘플링 편향(sampling bias) 때문에 발생할 수 있다.
1. 샘플링 잡음 (Sampling Noise)
- 샘플 크기가 작을 때, 우연에 의해 대표성이 떨어지는 현상이다.
- 소규모 설문 조사에서 특정 의견이 과대 대표될 수 있다.
2. 샘플링 편향 (Sampling Bias)
- 샘플링 방법 자체가 잘못되었을 때 발생하는 문제이다. 데이터가 많아도 편향된 방식으로 수집되면 대표성이 떨어진다.
📌 대표적인 샘플링 편향 사례: 1936년 미국 대통령 선거
1936년, 『The Literary Digest』는 천만 명을 대상으로 대규모 여론조사를 실시했다.
이 결과에 따르면, 랜던(Landon) 후보가 57%의 득표율로 승리할 것이라고 예측되었다.
하지만 실제 선거에서는 루스벨트(Roosevelt) 가 62%의 득표율로 당선되었다.
문제점은 조사 방법에 있었다.
- 부유층 편향:
- 전화번호부, 잡지 구독자 명부, 클럽 회원 명부를 기반으로 조사 대상자를 선정했다.
- 당시 전화 보급률이 낮아 부유층이 과대표되었고, 이들은 공화당(랜던)을 지지할 가능성이 높았다.
- 비응답 편향 (Nonresponse Bias):
- 조사 대상 중 응답률이 25% 미만이었다.
- 정치에 관심 없는 사람이나 『The Literary Digest』를 선호하지 않는 사람들은 응답하지 않았다.
- 이는 특정 성향을 가진 사람들의 의견이 과대 대표되는 결과를 낳았다.
대표성 있는 훈련 데이터 확보의 중요성
대표성이 부족한 데이터로 학습한 모델은 왜곡된 예측을 할 가능성이 높다.
실제 데이터를 더 확장해 보면 이를 명확히 알 수 있다.
- 누락된 국가 데이터를 추가했을 때 선형 모델이 크게 변경된다. 기존 모델(점선)과 비교했을 때, 새로운 모델(실선)은 더 많은 국가 데이터를 반영한다.
- 일부 매우 부유한 국가는 중간 수준 국가보다 행복하지 않으며, 반대로 일부 가난한 국가가 더 높은 삶의 만족도를 보이기도 한다.
이러한 결과를 보면, 단순한 선형 모델이 실제 데이터에서는 잘 작동하지 않을 수 있음을 확인할 수 있다.
결론적으로, 대표성 있는 훈련 데이터를 확보하는 것이 머신러닝 모델의 성능과 일반화에 결정적인 영향을 미친다.
1.5.3 낮은 품질의 데이터.
훈련 데이터 정제가 필요한 경우:일부 샘플 이상치라는게 명확할 경우, 일부 샘플에 특성 몇 개가 빠져있을 때
1.5.4 관련없는 특성
특성 공학: 훈련에 사용할 좋은 특성들을 찾는 것.
- 특성 선택- 가지고 있는 특성 중에서 훈련에 가장 유용한 특성 선택하기
- 특성 추출: 차원 축소 알고리즘처럼 특성을 결합하여 더 유용한 특성 만들기
- 데이터 수집: 새로운 데이터 수집해 새 특성 만들기
1.5.5 훈련 데이터 과대적합 Overfitting
머신러닝 모델은 사람처럼 과도하게 일반화할 수 있다. 훈련 데이터에는 너무 잘 맞지만 새로운 데이터에는 일반화되지 않는 현상을 과대적합(overfitting) 이라고 한다.
과대적합의 예시: 다항 회귀 모델
아래 그림에서는 고차원의 다항 회귀 모델이 훈련 데이터에 과대적합된 사례를 볼 수 있다.
이 모델은 단순한 선형 모델보다 훈련 데이터에 훨씬 더 잘 맞지만, 실제 예측에서는 신뢰하기 어렵다.
즉, 훈련 데이터의 패턴을 과하게 학습하여 새로운 데이터에서 일반화되지 못하는 문제가 발생한다.
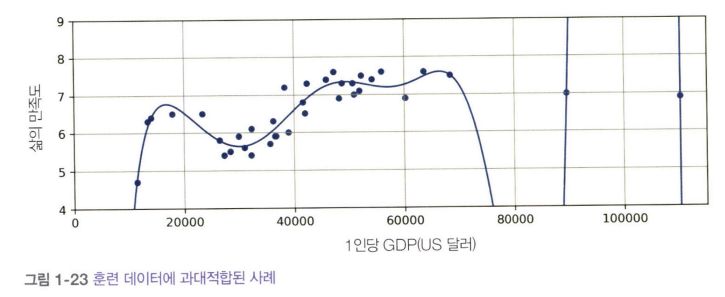
복잡한 모델과 샘플링 잡음
심층 신경망 같은 복잡한 모델은 데이터에서 미묘한 패턴을 감지할 수 있다. 하지만 훈련 세트에 잡음이 많거나 데이터셋이 너무 작으면, 모델은 샘플링 잡음(sampling noise) 을 학습하게 된다. 즉, 데이터에 존재하는 우연한 패턴까지 학습해버려 일반화되지 못하는 문제가 발생할 수 있다.
- 삶의 만족도를 예측하는 모델에 나라 이름 같은 관련 없는 특성을 추가한다고 해보자. 이 경우, 모델이 이상한 패턴을 감지할 수도 있다.
이상한 패턴-“이름에 ‘w’가 포함된 나라들의 삶의 만족도는 7보다 크다.”
이 규칙은 뉴질랜드(7.6), 노르웨이(7.3), 스웨덴(7.2), 스위스(7.5) 에서 맞을 수 있다. 그러나 이 규칙을 르완다나 짐바브웨에도 적용하면 신뢰할 수 X . 이는 단순히 훈련 데이터에서 우연히 발견된 패턴이며, 새로운 데이터에서는 적용되지 않을 가능성이 크다.
과대적합 해결 방법
과대적합은 훈련 데이터의 양과 잡음에 비해 모델이 너무 복잡할 때 발생한다.이를 해결하기 위한 몇 가지 방법이 있다.
1. 모델을 단순화한다.
- 파라미터 수가 적은 모델을 선택한다.
- 고차원 다항 모델 대신 선형 모델을 사용한다.
- 훈련 데이터의 특성을 줄인다.
- 모델에 제약을 가하여 단순화한다. (규제 적용)
2. 훈련 데이터를 늘린다.- 데이터가 많아질수록 모델이 특정 패턴에 집착하는 것을 방지할 수 있다.
3. 훈련 데이터의 잡음을 줄인다. - 오류 데이터를 수정하고, 이상치를 제거하여 모델이 불필요한 패턴을 학습하는 것을 막는다.
규제 (Regularization)
과대적합을 방지하는 방법 중 하나는 즉 규제(regularization) 를 적용하는 것이다.
- 예를 들어, 앞서 사용한 선형 모델은 다음과 같이 두 개의 모델 파라미터 θ₀(절편) 과 θ₁(기울기) 을 갖는다. 이는 모델이 데이터에 맞춰지는 자유도를 결정한다. 모델이 너무 복잡하면 규제를 적용해 기울기(θ₁)를 작게 만들어 모델을 단순화할 수 있다.
[그림 1-24]를 보면 세 가지 모델이 있다.
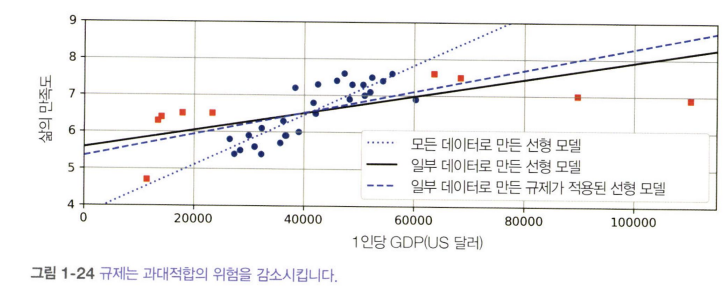
- 점선 모델: 원래 훈련 데이터(일부 국가만 사용)로 학습한 모델
- 파선 모델: 모든 국가 데이터를 포함하여 학습한 모델
- 실선 모델: 첫 번째 모델과 같은 데이터에 규제를 적용한 선형 모델
규제를 적용한 실선 모델은 훈련 데이터(원래 샘플)에는 덜 맞지만,
훈련에 사용되지 않은 새로운 샘플(추가된 국가)에는 더 잘 일반화된다.
하이퍼파라미터 튜닝의 중요성
규제의 강도는 하이퍼파라미터(hyperparameter) 가 결정한다. 하이퍼파라미터는 모델 자체의 파라미터가 아니라 학습 알고리즘의 파라미터이므로, 훈련 전에 지정해야 하며, 훈련하는 동안에는 고정된 값으로 유지된다.
- 하이퍼파라미터 값을 너무 크게 설정하면?
→ 모델이 거의 평평한 직선이 되어, 과대적합은 방지되지만 좋은 예측을 하지 못함. - 하이퍼파라미터 값을 너무 작게 설정하면?
→ 모델이 훈련 데이터에 과도하게 맞춰져 과대적합 발생 가능성이 높아짐. 따라서, 적절한 규제 강도를 찾는 것이 머신러닝 모델을 구축할 때 매우 중요한 과정이다.
1.5.6 훈련 데이터 Underfitting
- 과대적합의 반대, 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생.
- 삶의 만족도에 대한 선형 모델 : 현실은 이 모델보다 더 복잡하므로 훈련 샘플에서조차도 부정확한 예측을 만들 것이다.
- 내가 프로젝트로 했던 넷플릭스 순위 예측 플젝도 아마 과소적합됐을 가능성이 높다. 데이터는 4000개 정도의 빅데이터였지만 모델을 선형회귀를 썼고, 영화 흥행 성적에는 수익 말고도 여러 가지 요인들이 고려되는 등 현실 세계가 더 복잡하기 때문 과소 적합을 해결하기 위해서는 모델 파라미터가 더 많은 강력한 모델을 선택하고, 학습 알고리즘에 더 좋은 특성을 제공하고, 모델의 제약을 줄여야 한다.
정리
📌 1장 정리하기
머신러닝은 명시적인 규칙을 코딩하지 않고 기계가 데이터로부터 학습하여 어떤 작업을 더 잘하도록 만드는 것이다. 여러 종류의 머신러닝 시스템이 있다. 지도 학습과 비지도 학습, 배치 학습과 온라인 학습, 사례 기반 학습과 모델 기반 학습 등이다. 머신러닝 프로젝트에서는 훈련 세트에 데이터를 모아 학습 알고리즘에 주입. 학습 알고리즘이 모델 기반이면 훈련 세트에 모델을 맞추기 위해 모델 파라미터를 조정하고(즉, 훈련 세트에서 좋은 예측을 만들기 위해), 새로운 데이터에서도 좋은 예측을 만들 거라 기대. 알고리즘이 사례 기반이면 샘플을 기억하는 것이 학습이고 유사도 측정을 사용하여 학습한 샘플과 새로운 샘플을 비교하는 식으로 새로운 샘플에 일반화한다. • 훈련 세트가 너무 작거나, 대표성이 없거나, 잡음이 많고 관련없는 특성으로 오염되어 있다 면 시스템이 잘 작동하지 않는다(엉터리가 들어가면 엉터리가 나옵니다). 마지막으로 모델이 너무 단순하거나(과소적합된 경우) 너무 복잡하지 않아야 한다.(과대적합된 경우).1.6 테스트와 검증
모델이 새로운 샘플에서 얼마나 잘 일반화될지 평가하는 유일한 방법은 실제로 새로운 샘플에 적용해보는 것이다. 이 방법에는 두 가지 접근법이 있다.
-
실제 서비스에 모델을 배포하고 모니터링
- 모델이 잘 작동하면 문제없지만, 성능이 나쁘면 고객의 불만이 발생할 수 있다.
- 따라서 이 방법은 위험성이 크다.
-
훈련 데이터를 훈련 세트와 테스트 세트로 나누어 평가
- 훈련 세트(training set) → 모델을 학습하는 데 사용
- 테스트 세트(test set) → 모델을 평가하는 데 사용
- 테스트 세트에서 측정한 오차를 일반화 오차(generalization error) 또는 외부 샘플 오차(out-of-sample error) 라고 한다.
- 이 값을 통해 모델이 이전에 본 적 없는 새로운 데이터에서도 얼마나 잘 작동할지 예측할 수 있다.
📌 과대적합(Overfitting)과 일반화 오차
- 훈련 오차(training error): 훈련 데이터에서의 오차
- 일반화 오차(generalization error): 새로운 데이터에서의 오차
- 훈련 오차는 작은데 일반화 오차가 크다면? → 모델이 과대적합(Overfitting) 되었음을 의미한다.
훈련 세트 vs 테스트 세트 비율
- 일반적으로 80%를 훈련 데이터, 20%를 테스트 데이터로 분할. 데이터셋 크기에 따라 다름 (예: 샘플이 천만 개라면, 1%만 테스트 데이터로 사용해도 충분할 수 있음)
1.6.1 하이퍼파라미터 튜닝과 모델 선택
📌 모델 선택 방법
- 모델을 평가하는 가장 간단한 방법은 테스트 세트에서 성능을 비교하는 것이다.
- 선형 모델과 다항 모델 중 어떤 것이 더 좋은지 결정하려면:
- 두 모델을 훈련 세트로 학습시킨다.
- 두 모델을 테스트 세트에서 평가하여 일반화 성능을 비교한다.
- 선형 모델과 다항 모델 중 어떤 것이 더 좋은지 결정하려면:
⚠️ 검증 세트(Validation Set)의 크기 문제
- 검증 세트가 너무 작으면? → 모델 평가가 정확하지 않을 수 있음.
- 검증 세트가 너무 크면? → 훈련 세트가 작아져 최적의 모델을 선택하기 어려워짐.
- 마라톤 선수를 뽑으려는데 단거리 주자만 보고 선택하는 것과 같다.
✅ Cross-Validation
이 문제를 해결하는 방법 중 하나가 교차 검증(cross-validation) 이다.
- 작은 검증 세트를 여러 개 사용하여 반복적인 평가 수행
- 검증 세트마다 나머지 데이터로 모델을 훈련하고, 검증 세트에서 성능 평가
- 모든 검증 결과의 평균을 내어 모델의 성능을 더욱 정확하게 측정
- 단점: 훈련 시간이 검증 세트 개수만큼 증가 (연산량 증가)
📌 하이퍼파라미터 튜닝과 과적합 방지
🎯 하이퍼파라미터 선택 문제
- 모델에 규제(Regularization) 를 적용하여 과대적합을 방지하려고 한다고 가정하자.이때, 최적의 하이퍼파라미터 값은 어떻게 선택할까?
- 100개의 하이퍼파라미터 값으로 100개의 다른 모델을 학습
- 테스트 세트에서 일반화 오차가 가장 낮은 모델을 선택 (예: 오차 5%)
- 이 모델을 실제 서비스에 배포했더니 실제 오차가 15%
→ 성능이 기대보다 나쁨. 왜 그럴까?
💡 문제점
- 여러 번 테스트 세트에서 일반화 오차를 측정했기 때문에 테스트 세트에 최적화된 모델이 학습됨. 즉, 테스트 세트 자체에 과적합(overfitting)된 모델이 됨.
- 새로운 데이터에서 잘 작동하지 않을 가능성이 높음.
1.6.2 홀드아웃 검증 (Holdout Validation)
✅ 홀드아웃 검증(Validation Set) 방법
이 문제를 해결하는 일반적인 방법은 홀드아웃 검증(holdout validation) 을 사용하는 것이다.
🔹 홀드아웃 검증 과정
-
훈련 세트를 다시 두 부분으로 나눈다.
- 훈련 데이터(training set): 모델을 학습하는 데 사용
- 검증 데이터(validation set): 여러 모델을 비교하는 데 사용
- 검증 데이터는 개발 세트(development set) 또는 데브 세트(dev set) 라고도 한다.
-
여러 모델을 훈련하여 검증 세트에서 성능 평가
- 다양한 하이퍼파라미터 값으로 모델을 훈련하고 검증 세트에서 성능 비교
- 검증 성능이 가장 높은 모델을 선택
-
최종 모델 훈련
- best 모델을 검증 세트를 포함한 전체 훈련 데이터로 다시 학습
- 이제 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 추정
- 이를 통해 실제 서비스에서 잘 작동할 가능성이 높은 모델을 선택 가능!
📌 정리: 머신러닝 모델 평가 과정
-
훈련 데이터를 훈련 세트와 테스트 세트로 분할
- 일반적으로 80% 훈련, 20% 테스트
- 테스트 세트에서 성능을 평가하여 일반화 오차를 측정
-
모델 선택 과정
- 다양한 모델을 훈련하고 검증 세트에서 성능 평가
- 성능이 가장 좋은 모델을 선택
-
하이퍼파라미터 튜닝
- 여러 하이퍼파라미터를 실험하고 최적의 조합을 찾음
- 검증 세트에서 가장 좋은 성능을 낸 모델을 선택
-
최종 모델 훈련 및 평가
- 최선의 모델을 전체 훈련 데이터로 다시 학습
- 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 최종 확인
- 서비스에 배포하기 전에 모델이 실제 환경에서도 잘 작동할지 확인
💡 핵심 요점
- 테스트 세트는 최종 평가를 위해 남겨둬야 함 (테스트 세트에 맞춰진 모델은 실제 환경에서 성능이 떨어질 수 있음)
- 교차 검증을 활용하면 더 정확한 모델 평가 가능
- 홀드아웃 검증(Validation Set)을 사용하여 모델을 튜닝한 후 최종 테스트 진행