Attention is all you need
March 2025 (2219 Words, 13 Minutes)
Abstract
- 제안한게 뭐냐. 2. 의의(차별점) 이 뭐냐 3. Attention 이 뭐냐
번역본
주요 시퀀스 변환 모델은 인코더와 디코더를 포함하는 복잡한 순환 신경망(RNN) 또는 합성곱 신경망(CNN)에 기반을 둔다. 성능이 가장 뛰어난 모델은 또한 어텐션(attention) 메커니즘을 통해 인코더와 디코더를 연결한다. 우리는 순환 구조와 합성곱 연산을 완전히 배제하고 오직 어텐션 메커니즘만으로 구성된 새로운 간단한 네트워크 아키텍처인 트랜스포머(Transformer)를 제안한다. 두 가지 기계 번역 작업에서의 실험 결과, 이 모델은 훨씬 더 병렬화가 용이하고 학습 시간이 현저히 적게 소요되면서도 우수한 품질을 보인다. 우리의 모델은 WMT 2014 영어-독일어 번역 작업에서 28.4 BLEU 점수를 달성하며, 앙상블 모델을 포함한 기존 최고 기록을 2 BLEU 이상 앞질렀다. WMT 2014 영어-프랑스어 번역 작업에서는 8개의 GPU로 3.5일간 학습한 후 41.8 BLEU라는 단일 모델 기준 새로운 최첨단 성적을 기록했는데, 이는 문헌에 보고된 최고 모델들의 학습 비용에 비해 극히 일부에 불과하다. 우리는 트랜스포머가 영어 구성 성분 구문 분석(constituency parsing) 작업에 대량 및 제한된 학습 데이터 모두로 성공적으로 적용됨으로써 다른 작업으로도 잘 일반화됨을 보여준다.
핵심 문장
- ” We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. “
- “We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data”
Introduction
번역본 순환 신경망(RNN), 특히 장단기 메모리(LSTM)[13]와 게이트 순환 신경망(GRU)[7]은 언어 모델링 및 기계 번역과 같은 시퀀스 모델링 및 변환 문제에서 최첨단 접근법으로 확고히 자리잡았다. 이후로 수많은 연구가 순환 언어 모델과 인코더-디코더 아키텍처의 한계를 넓히기 위해 지속되어 왔다.
순환 모델은 일반적으로 입력 및 출력 시퀀스의 심볼 위치를 따라 계산을 구성한다. 계산 시간 단계와 위치를 맞추어, 이전 은닉 상태(ht−1)와 현재 위치(t)의 입력을 함수로 사용하여 일련의 은닉 상태(ht)를 생성한다. 이러한 본질적인 순차적 특성은 훈련 예제 내에서의 병렬화를 방해하며, 이는 시퀀스 길이가 길어질수록 더욱 중요해진다. 메모리 제약으로 인해 예제 간 배치 처리에 한계가 있기 때문이다. 최근 연구에서는 인수분해 기법과 조건부 계산을 통해 계산 효율성을 크게 향상시켰으며, 후자의 경우 모델 성능도 개선되었다. 그러나 순차 계산의 근본적인 제약은 여전히 남아 있다.
- 병렬화 안 됨, RNN블럭의 특성상 반복적으로 해결할 수 밖에 없기 때문에 블럭들 자체를 없애는게 낫다고 함 -> attention . 다 attention 블럭으로 바꾼 것.
어텐션 메커니즘은 다양한 작업에서 강력한 시퀀스 모델링 및 변환 모델의 핵심 요소가 되었으며, 입력 또는 출력 시퀸스 내 거리에 관계없이 종속성을 모델링할 수 있게 한다. 그러나 극少数 사례를 제외하면, 이러한 어텐션 메커니즘은 순환 신경망과 함께 사용된다.
본 연구에서는 순환 구조를 배제하고 오직 어텐션 메커니즘만으로 입력과 출력 간의 전역적 종속성을 포착하는 트랜스포머(Transformer) 모델 아키텍처를 제안한다. 트랜스포머는 훨씬 더 많은 병렬화를 가능하게 하며, 8개의 P100 GPU로 단 12시간만 훈련해도 번역 품질에서 새로운 최첨단 성능을 달성할 수 있다.
핵심 문장
-
“In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.”
-
즉 RNN, LSTM, GRU 등 순환 신경망 기반 모델은 시퀀스 모델링(예: 번역)에서 SOTA를 달성했으나, 순차적 계산(sequential processing)으로 인해 병렬화가 불가능하다는 근본적 문제가 있음. 어텐션 메커니즘이 RNN과 결합되어 사용되긴 했지만, 여전히 순환 구조에 의존적. 따라서 순환 구조를 완전히 제거하고 어텐션 메커니즘만으로 구성된 최초의 모델인 트랜스포머를 제안.
Background
(seq-seq단점)
- hard to compress the sentence: Forget earlier word representations 앞에 있는 정보량 손실.
- Different Information may be relevant at different steps = 특정 단어의 위치에 따라 단어의 정보량이 민감하게 변한다.
1번 문제 해결하기 위해 Encoder에서 Bidirectional LSTM을 도입하여 손실을 최소화하려 했다.
2번 문제를 해결하기 위해서는 Attention!
What is Attention?
인풋 데이터들이 위치에 상관 없이 전체 문장에서 얼마나 중요한가
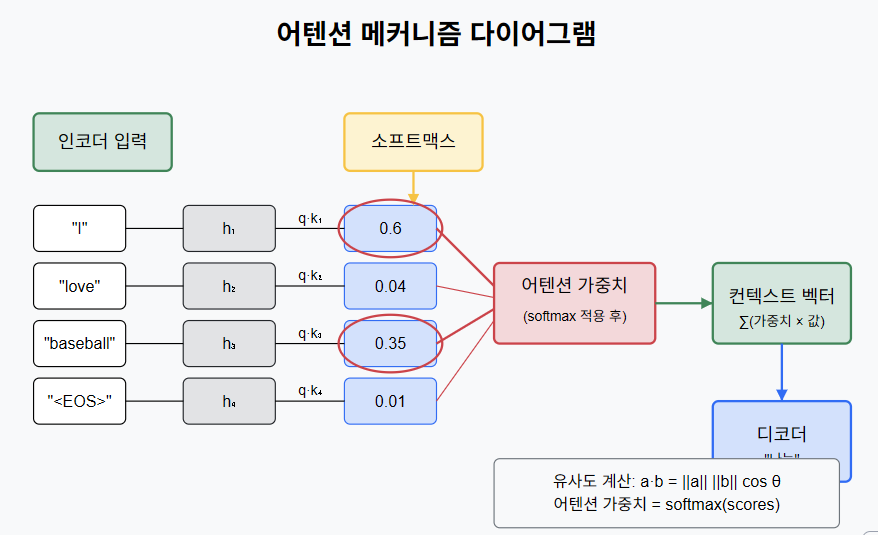
쿼리(Query), 키(Key), 값(Value) 벡터 계산
쿼리: 현재 디코더의 상태 (내가 무엇을 찾고 있는가?) 키: 각 인코더 출력 표현 (각 입력 단어의 특성) 값: 실제 인코더의 정보 (실제로 가져올 내용)
유사도 계산
쿼리와 각 키 사이의 내적(dot product) 계산: score = Query · Key
- 유사도 계산: 두 벡터의 내적 for each encoder’s representation and hidden state of decoder
- $a \cdot b = |a| |b| \cos \theta$
- 두 벡터가 같은 방향을 가리키는지 측정
가중치 변환 : 계산된 유사도 점수들을 softmax 에 통과시킴. 결과적으로 모든 가중치의 합은 1이 됨. attention weights=softmax(scores) 가중 합계:각 값(Value) 벡터에 해당 가중치를 곱하고 합산. context vector=∑(attention weights×values)
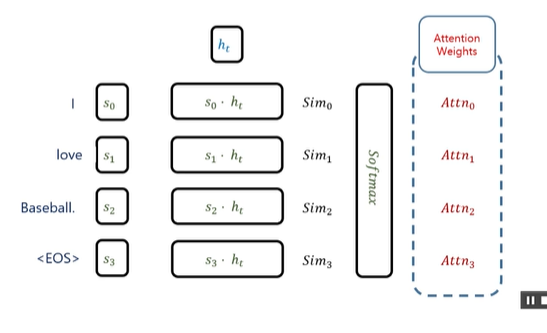
Attention input
- Encoder states: $( s_1, s_2, \dots, s_m )$
- Decoder state at time $( t ): ( h_t )$
Attention scores:
$text{score}(h_t, s_k)$: “How relevant is source token k for target step t?” $ [ \text{score}(h_t, s_k), \quad k = 1 \dots m ] $
Attention weights(softmax)
$ [ a_k^{(t)} = \frac{\exp(\text{score}(h_t, s_k))}{\sum_{i=1}^{m} \exp(\text{score}(h_t, s_i))}, \quad k = 1 \dots m ] $ $a_k^{(t)}$: attention weight for source token k at decoder step t
Attention Output (Context Vector)
$
[
c^{(t)} = a_1^{(t)} s_1 + a_2^{(t)} s_2 + \cdots + a_m^{(t)} s_m
]
$
$c^{(t)}$: source context for decoder step t
sequential 계산을 줄이려는 목표는 Extended Neural GPU, ByteNet, ConvS2S의 기초가 되며, 이들 모델은 모두 합성곱 신경망(CNN)을 기본 구성 요소로 사용하여 모든 입력 및 출력 위치에 대한 은닉 표현을 병렬로 계산한다. 이러한 모델들에서는 두 임의의 입력 또는 출력 위치 간 신호를 연관시키는 데 필요한 연산량이 위치 간 거리에 따라 증가하는데, ConvS2S는 선형적으로, ByteNet는 로그 스케일로 증가한다. 이로 인해 먼 위치 간 의존성을 학습하기가 더 어려워진다.
트랜스포머에서는 이를 상수 횟수의 연산으로 줄였지만, 어텐션 가중치 위치를 평균화함으로써 발생하는 효과적인 해상도 감소라는 대가가 따른다. 우리는 이 문제를 3.2절에서 설명할 다중 헤드 어텐션(Multi-Head Attention)으로 해결했다.
자기 어텐션(Self-attention, 때로는 내부 어텐션(intra-attention)이라고도 함)은 단일 시퀀스의 서로 다른 위치들을 연관시켜 시퀀스의 표현을 계산하는 어텐션 메커니즘이다.
종단 간 메모리 네트워크(End-to-end memory networks)는 시퀀스 정렬 순환 대신 반복적 어텐션 메커니즘을 기반으로 하며, 간단한 언어 질의응답 및 언어 모델링 작업에서 우수한 성능을 보인다[34].
그러나 우리가 아는 한, 트랜스포머는 시퀀스 정렬 RNN이나 합성곱을 전혀 사용하지 않고 순수하게 자기 어텐션만으로 입력 및 출력 표현을 계산하는 최초의 변환(transduction) 모델이다. 다음 섹션에서는 트랜스포머를 설명하고, 자기 어텐션의 동기를 제시하며,과 같은 모델 대비 장점에 대해 논의할 것이다.
그니까 RNN 과 CNN을 완전히 버리고 self attention 만으로 입력과 출력의 관계를 학습해 병렬화와 장거리 의존성 처리를 동시에 해결한 최초의 모델이란 것이다
Model architecture
- 대부분의 경쟁력 있는 신경망 시퀀스 변환 모델은 인코더-디코더 구조를 사용. RNN cell block -> Attention transformer 도 마찬가지로 , 인코더는 입력 시퀀스를 연속적 표현으로 매핑하고, 디코더는 이를 바탕으로 한 번에 하나씩(auto-regressive) 출력 시퀀스를 생성
- 인코더: 입력 (x₁,…,xₙ) → 연속 표현 (z₁,…,zₙ) 변환
- 디코더: z를 기반으로 (y₁,…,yₘ) 생성 (이전 출력을 다음 입력으로 사용)
Transformer의 기본 골격
3.1 Encoder and Decoder Stacks
transformer의 핵심!
-
인코더(Encoder): 6개의 동일한 레이어로 구성되며, 각 레이어는 2개의 서브 레이어를 가짐
- 멀티 헤드 셀프 어텐션(Self Attention):
- 위치별 완전 연결 Feed Forward 네트워크
-
각 서브 레이어에는 잔차 연결(Residual Connection) + 레이어 정규화 적용 → 출력: LayerNorm(x + Sublayer(x))
-
모든 출력 차원은 d_model = 512로 통일
-
디코더(Decoder):
- 6개의 동일한 레이어로 구성되며, 인코더의 2개 서브 레이어 외에 추가 서브 레이어 포함 3. 인코더 출력에 대한 멀티 헤드 어텐션
- 마스크드 셀프 어텐션 적용:
- 현재 위치 이후의 단어를 참조하지 못하도록 차단 (Auto-regressive 성질 보장)
- 출력 임베딩을 한 위치씩 오프셋하여 i번째 예측은 i-1까지의 출력만 의존하도록 함
3.2 Attention
-
Attention 이 뭐냐? 주어진 query와 key-value 쌍들을 입력받아, query와 key의 유사도에 따라 value들을 가중합해 출력하는 메커니즘
- 쿼리(고정) <-> encoded vectors : 인코딩된 벡터들을 의미 벡터로 변환해주는 가중치치 가 학습이 됨.
- 기존의 어텐션과 다르게 , parellel 하게 계산하기 위해 셀프 어텐션은 인코딩된 벡터들을 임베딩된 차원으로 변경해주는 matrix를 학습
- Q, K 를 담당하는 weight 존재. $W_q$, $W_k$ 들이 학습이 되는 것.
- Aggregate information(value) of each word
- embedding 을 해서 컨텍스트를 매번 뽑을 필요 없이, 한번에 모든 토큰을 계산을 해 놓고 아웃풋을 뽑을 수 있음. 반복했던 것을 한번에 할 수 있음 = Matrix Multiplication
what is self attention
-
같은 시퀀스 내의 모든 요소들 간의 관계(의존성)를 계산하는 메커니즘(임베딩 방식 중 하나). 각 단어가 동일한 시퀀스의 다른 단어들과 어떻게 연관되는지 Q, K 사이의 관계성을 계산하여 가중치(attention score)로 표현. 어텐션은 각 쿼리에 대해 닷 프로덕트로 진행. 셀프 어텐션도 모든 워드 토큰들에 대해 similarity 계산.
- 쿼리, 키, 값 벡터 생성 -> attention score 계산, Attention Matrix 도출 -> Value를 곱하여 가중합 출력 = Updated Query
- self attention 이 transformer 가 제시하는 가장 새로운 기법.
셀프 어텐션의 혁신성 vs. 기존 방식
RNN/CNN의 한계:
RNN: 순차적 처리 → 병렬화 불가, 장기 의존성 학습 어려움. CNN: 지역적 패턴 중심 → 긴 시퀀스 관계 포착 힘듦.
셀프 어텐션의 장점
병렬 처리 가능: 컨텍스트를 한 번에 뽑아냄 즉, 모든 위치 간 관계를 한 번에 계산. 장거리 의존성 학습: 시퀀스 길이에 무관하게 직접 연결. 해석 가능성: 어텐션 가중치로 모델의 결정 근거 분석 가능.
3.2.1 Scaled Dot -Product Attention
what is softmax
-
소프트맥스 함수는 입력 벡터를 확률 분포로 변환하는 활성화 함수. 다중 클래스 분류(Multi-class Classification)에서 출력층에 주로 사용.
-
Gradient : 벡터 미적분학에서 나온 개념으로, 함수의 최대 증가 방향을 가리키는 벡터. 머신러닝에서는 손실 함수를 최소화하기 위해 모델 파라미터를 조정하는 데 사용.
-
Backpropagation 과정에서 손실 함수의 gradient 를 계산해 가중치를 업데이트함. 즉 경사 하강법의 핵심 요소.
한 줄로 요약하자면- scaled dot product attention 은 Query와 Key의 내적을 √dk로 나눈 후 softmax를 적용해 value들의 가중합을 구하는 효율적인 attention 메커니즘이다.이때 내적 (dot product) 로 유사도를 측정하고, √dk로 나누는 이유는 softmax 의 gradient 가 너무 작아지는 문제를 방지하기 위해서다.
- 쿼리, 키, 밸류 의 Q K V 가 입력되면 (인코더에) 모두 행렬로 계산하기 때문에 병렬 연산이 가능해진다.
- Q * K => Relational Matrix. R(Attention weight)*V => Attended Query.
- Optimization: $W_q$, $W_k$, $W_v$
$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\ $
3.2.2 Multi - Head Attention
멀티 헤드 attention 은 여러 개의 서로 다른 선형 변환된 Q, K, V를 병렬로 attention 한 뒤 결과를 결합해 더 풍부한 표현력을 갖는 attention을 구현한다. 즉 한 번의 attention만으로는 다양한 의미 포착이 어렵기에 여러 “head”로 나누어 다양한 표현 공간을 동시에 학습하는 것이다. 이때 차원을 나누어서 계산하므로 연산량은 거의 동일하다.
$[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, …, \text{head}_h)W^O ]$
$[ \text{where } \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) ]$
즉 기존 RNN/LSTM의 순차적 계산 한계를 극복하고, 병렬처리와 장기 의존성 처리 가능. Multi-Head는 다양한 의미 공간(subspace)에서 attention을 수행하여 더 풍부한 표현력을 가짐
3.2.3 Applications of Attention in our Model
Transformer uses multi head attention to three ways:
- “인코더-디코더 어텐션(encoder-decoder attention)” 레이어:
- queries come from the previous decoder layer
- keys and values come from output of the encoder
- 디코더의 모든 위치가 입력 시퀀스의 모든 위치에 주목(attend)할 수 있도록 함
일차적으로는 sequence-to-sequence 모델의 전형적인 인코더 디코더 어텐션 메커니즘을 모방함.
- 인코더의 셀프-어텐션(self-attention) 레이어:
- in the self attention layer: 모든 키, 값, 쿼리가 동일한 출처(이전 인코더 레이어의 출력)에서 옴
- 디코더의 셀프-어텐션 레이어:
- 디코더의 각 위치는 자신보다 이전 위치까지의 모든 디코더 위치에 “Attention” 할 수 있음
- Scaled dot -product attention 내부에서 , 소프트맥스 입력 값을 masking( -무한대로 설정 함)
- mask: 한번에 각각 계산되도록 함.인코더를 오른쪽으로 갖고 와서 마스킹을 하는 것
인코더-디코더 어텐션: 디코더가 인코더 출력 전체를 참조, 인코더가 자신의 이전 레이어를 참조 + 디코더가 과거 위치만 참조하도록 마스킹을 적용
3.3
- 인코더와 디코더의 각 층에는 어텐션 서브층 외에도 위치별로 독립적으로 적용되는 동일한 구조의 2층 피드포워드 신경망(ReLU 활성화 포함)이 존재하며, 입력/출력 차원은 512, 은닉층 차원은 2048이다
- 위치별 동일 처리 + 512→2048→512 차원 변환
3.4
-
입력/출력 토큰을 dmodel 차원 벡터로 변환하는 임베딩 층과 소프트맥스 층의 가중치를 공유하며, 임베딩 값에 √dmodel을 곱해 스케일링한다
-
표 1에서 셀프 어텐션의 핵심 장점은 O(1) 최대 경로 길이로 장기 의존성 포착이 RNN(O(n))보다 우수함을 강조.
3.5 positional Encoding
순서 정보를 주입하기 위해 사인/코사인 함수로 생성된 고정형 위치 인코딩을 입력 임베딩에 더함.
- positional encoding + 픽셀 = vision transformer
4. Why self-attention
Sequence 모델링에서 Self-Attention이 RNN/CNN보다 왜 더 효율적이고 적합한지를 세 가지 관점에서 비교함.
- 계산 복잡도
- Self-Attention은 전체 시퀀스를 한 번에 처리할 수 있지만, 계산량은 n²에 비례, But 병렬화 가능
- 병렬화 가능
- Self-Attention은 모든 위치를 동시에 계산할 수 있어 → 병렬 처리에 유리
- 최대 경로 길이
- Self-Attention은 모든 단어 간 직접 연결 가능 → 장거리 의존성 학습에 유리
- RNN은 긴 시퀀스를 따라가야 하므로 장거리 학습이 어려움
5.1~5.5 Training
- 대규모 병렬 학습 + warmup 기반 동적 학습들
- 학습률 공식으로는 초기 선형 증가 -> 이후 스텝 수 제곱근 역비례 감소
5.3 optimizer ->
- Adam 사용. 초반 4,000스텝: 학습률을 선형 증가. 이후: 학습률을 스텝 수의 제곱근에 반비례하게 감소
5.4 정규화 ->
- 드롭아웃과 라벨 스무딩으로 정규화, BLEU 점수 향상에 기여.
-
초반 예열(warmup): 갑작스러운 큰 학습률로 인한 불안정성 방지.
-
후반 감소: 정밀한 최적화를 위해 천천히 조정.
- Adam + 스케줄링: 빠르면서도 안정적인 학습 가능.
6. 결과
6.1 Machine Translation
Transformer 빅 모델이 WMT 2014 영→독/영→프 번역에서 기존 최고 기록을 2.0 BLEU 이상 경신하며, 훈련 비용은 1/4로 절감했다.
- 즉 적은 자원으로 높은 정확도를 달성했고, 단일 모델로 앙상블 성능을 뛰어넘음.
6.2 Model Variations
- 트랜스포머의 핵심 구성 요소를 실험적으로 분석한 결과, 멀티헤드 어텐션과 적절한 키 차원 (dk), dropout 이 성능에 가장 큰 영향을 미쳤다.
테이블 해석
- 어텐션 헤드 수 : 단일 헤드 사용시 BLEU 0.9 하락 -> 멀티헤드 필수적.하지만 헤드 수 과도 증가 시 성능 저하 -> 적정 밸런스 필요.
- 어텐션 키 차원 (dk) : dk 축소 시 성능 하락. dot product의 한계 노출. 복잡한 호환성 함수가 더 유용할 수 있음.
- 큰 모델 -> 더 높은 성능. 드롭아웃 -> 과적합 방지 효과 큼.
- 위치 인코딩.
what is attention head
6.3 English Consistency Parsing
- Transformer가 영어 구문 분석(Constituency Parsing)에서도 RNN 기반 모델을 능가하며, 준지도 학습 시 SOTA에 근접한 성능을 달성했다.
- 출력이 입력보다 훨씬 길고 구문 규칙이 엄격한 태스크에서도 일반화 가능하여 구조적 제약 극복함
Conclusion
“For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers”
“We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.”