GPT revolution
March 2025 (1033 Words, 6 Minutes)
ChatGPT를 활용하는 이유
- 대화형 인터페이스: 실제 전문가와 대화하는 것과 유사한 경험을 제공한다.
- 접근성: 복잡한 기술 지식 없이 누구나 활용할 수 있다.
- RLHF(Reinforcement Learning from Human Feedback): 인간의 피드백을 통한 강화학습으로 자연스러운 응답을 생성한다..
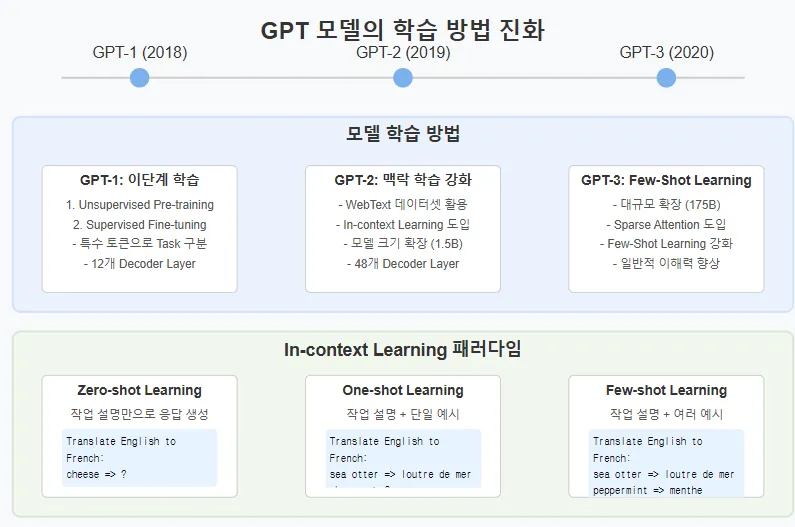
GPT 1
- 모델 구조: GPT-1은 Transformer 디코더만으로 구성된 언어 모델로, 총 12개의 디코더 레이어(약 1억 1천7백만 개의 파라미터)로 이루어져 있다. 각 디코더 블록은 마스크드(masked) 멀티-헤드 자기어텐션과 포지션별 피드포워드 네트워크로 구성되며, 각 하위 모듈 뒤에는 레이어 정규화(LayerNorm)와 잔차 연결이 적용된다.
- 미래 위치의 단어는 어텐션에서 마스킹되어 오로지 이전 단어들만 참고하게 함으로써, GPT-1은 주어진 시퀀스에서 다음 단어를 예측하는 방식으로 언어 모델링을 수행한다. 활성화 함수로는 Gaussian Error Linear Unit (GELU)를 사용했고, 위치 임베딩은 Transformer 원 논문과 달리 학습 가능한 임베딩을 도입한다.
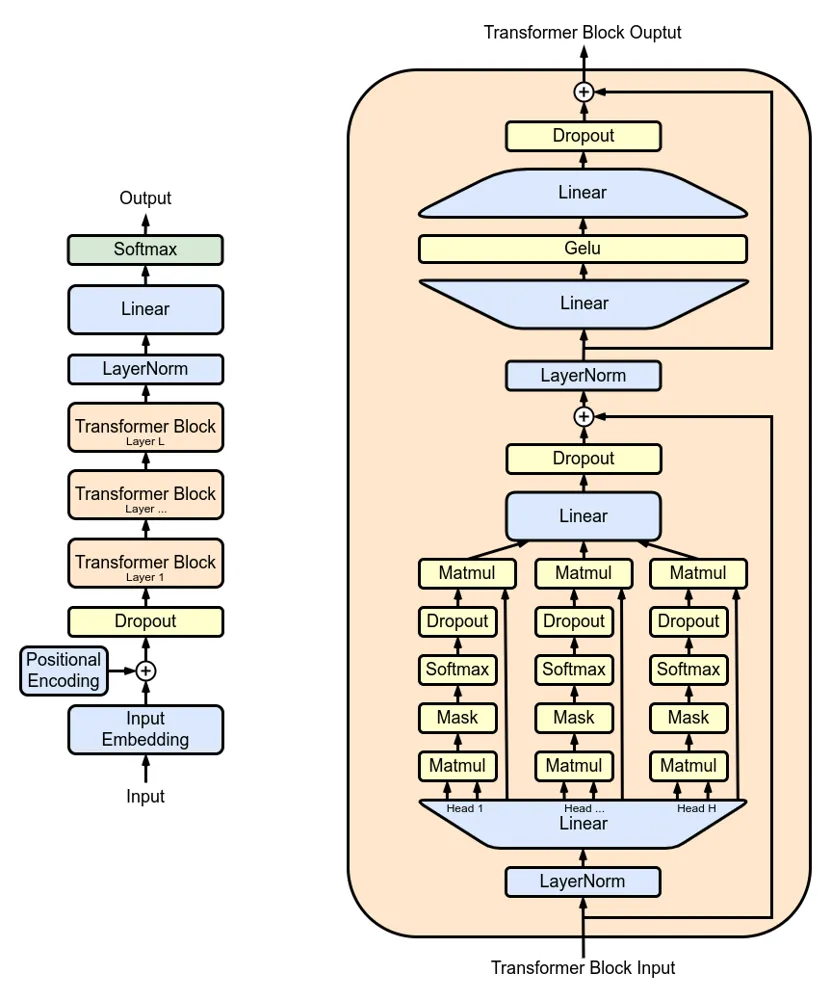
GPT 모델의 전체 구조를 개략적으로 나타낸 그림. 왼쪽에는 입력 토큰에 대한 임베딩 벡터와 위치 인코딩이 더해져 디코더 블록들의 스택으로 전달되는 과정을 보여주고, 오른쪽에는 단일 Transformer 디코더 블록의 내부 구성을 확대해서 나타냈는데, 각 디코더 블록은 (아래쪽부터) LayerNorm을 시작으로 멀티-헤드 어텐션 (Head 1 … Head H) 및 마스킹, 소프트맥스 연산과 드롭아웃, 그리고 상단의 피드포워드 층(Linear-GELU-Linear)으로 이루어진다. 각 서브층 출력은 잔차 연결(+ 기호로 표기)로 블록 입력과 더해진 뒤 LayerNorm을 거쳐 다음 단계로 전달된다.
- 사전훈련(비지도 학습): GPT-1은 대용량 텍스트 코퍼스에 대한 언어모델 사전훈련을 통해 특징 표현을 학습함.
- 구체적으로 BooksCorpus 데이터셋 (약 7천 권 분량의 장편 소설 텍스트, 8억 단어 규모)으로부터 연속적인 문장들의 다음 단어를 예측하도록 GPT 모델을 비지도 학습시켰다.
- 토크나이제이션은 대소문자 구분 및 구두점, 공백 등을 처리하기 위해 spaCy 토크나이저로 초기 전처리를 한 뒤, 어휘 크기 40,000의 Byte-Pair Encoding (BPE) 방식으로 단어를 서브워드(subword) 단위로 분할하여 사용했다.
이러한 BPE 기반 토크나이저 덕분에 희귀 단어도 서브워드로 쪼개어 표현할 수 있었고, 전체 말뭉치에 대해 OOV(어휘 밖) 문제 없이 학습이 가능했다.
파인튜닝(지도 학습):
사전훈련된 GPT-1 모델은 다양한 다운스트림 NLP 작업에 대해 지도 학습으로 미세조정(fine-tuning)되었는데,
- 파인튜닝 단계에서는 사전훈련된 모델의 파라미터를 초기화 값으로 사용하고, 각 과제에 맞게 약간의 구조를 덧붙학습한다. - 예를 들어 문서 분류나 문장 관계 판단과 같은 작업에서는 입력 문장 끝에 특별 토큰을 추가하고 해당 위치의 출력 벡터를 받아 소프트맥스 분류기를 통과시키는 방식을 사용하였고,
- 질의응답(Task Q&A)의 경우 지문과 질문에 후보 정답을 이어붙인 입력을 만들고 모델의 확률 출력으로 정답을 선택했다.
- 모델 아키텍처 자체의 변경은 최소화되었으며, 주로 입력 형태를 과제에 맞게 변형하고 출력에 작은 추가 레이어를 붙이는 정도로 해결했다.
- 이러한 간단한 파인튜닝 방법에도 불구하고 GPT-1은 자연어 추론(MNLI 등)이나 상식 질문응답(RACE, Story Cloze) 등 여러 벤치마크에서 당시 최신 기법들을 능가하는 성능 향상을 보여준다.
GPT-2 (2019) – 구조 개선과 Zero-shot 학습
구조적 개선점:
- GPT-2는 GPT-1의 기본 구조를 유지하면서 모델 규모와 입력 길이 등을 대폭 확장한 버전.
- GPT-1이 12개 레이어(117M 파라미터, hidden size 768)였던 데 반해, GPT-2는 최대 48개 레이어로 깊어졌고(hidden size 1600) 파라미터 수가 약 15억 개에 달하는 모델(GPT-2 1.5B)까지 출시
- 내부적으로는 프리-액티베이션 레이어정규화(pre-LN) 기법을 도입하여, 각 서브층 (어텐션/FFN) 입력에 LayerNorm을 적용하고 마지막에도 LayerNorm을 한 번 더 두어 깊은 네트워크 학습의 안정성을 높임.
- 또한 Residual 경로의 초기값 스케일을 $1/\sqrt{N}$ (N=레이어 수)로 줄이는 등 파라미터 초기화 방식을 개선하여, 깊이가 깊어져도 그래디언트 분산이 커지지 않도록 함.
- 이처럼 모델 용량을 크게 늘린 결과, GPT-2의 가장 큰 모델은 GPT-1보다 매개변수가 한 10배 이상 많고 표현력도 훨씬 커짐.
- (+) 컨텍스트 길이도 두 배로 확장하여 GPT-2는 한 번에 최대 1024 토큰까지 처리할 수 있어, 더 긴 입력 문맥을 활용한 생성이 가능
- Byte-Level BPE 덕분에 GPT-2는 이모지나 한자 같은 특수 문자도 “unknown” 없이 처리할 수 있고, 임의의 텍스트를 손실 없이 토큰화 및 복원 가능.
In-Context Learning과 Zero-Shot 활용:
- GPT-2의 가장 큰 혁신 중 하나는 별도 지도학습 없이도 모델 자체를 다양한 작업에 활용할 수 있다는 점.
- 즉, GPT-2는 대규모 비지도 학습만으로도 모델 내부에 일반적인 언어 이해/생성 능력을 습득하여, 추론 시에 문맥(context)만 주어지면 새로운 작업을 수행할 수 있다는 것을 보여주었다.
-
이를 Zero-Shot 학습 또는 In-Context Learning이라고 부르는데, GPT-2 논문에서는 거대한 언어모델이 충분히 학습되면 자연스럽게 발생하는 예시만으로도 작업을 학습한다는 흥미로운 결과를 보고했다.
- 맥락 기반 학습 능력은 GPT-1에서는 두드러지지 않았던 것으로, 다만 GPT-2 시점에서는 이러한 zero-shot 성능이 개별 작업의 최신 기법을 완전히 뛰어넘을 정도는 아니었지만, 모델을 추가 훈련하지 않고도 다양한 과제를 해결할 가능성을 보여주었다는 점에서 큰 의의가 있다.
학습 데이터 확장:
- GPT-2는 학습 데이터 측면에서도 GPT-1보다 큰 변화를 줌. 우선 사전훈련 데이터셋으로 방대한 웹 크롤링 말뭉치인 WebText를 구축하여 사용.
- WebText는 Reddit에서 높은 추천 점수를 받은 링크들을 크롤링하여 얻은 웹 페이지들로 구성.
- 이렇게 질 높은 웹텍스트로 이루어진 대용량 코퍼스를 사용함으로써 GPT-2는 소설 (BooksCorpus) 위주였던 GPT-1보다 주제와 도메인이 다양한 언어 패턴을 학습할 수 있었다.
GPT-3 (2020) – 대규모화와 Few-Shot 학습
- 모델 규모 확장과 Sparse Attention: GPT-3는 GPT 시리즈의 세 번째 모델로, 모델 크기를 비약적으로 확대하여 성능을 끌어올린 사례. 가장 큰 GPT-3 모델은 1750억개의 파라미터를 가지며, 이는 GPT-2(15억) 대비 100배 이상 큰 규모입니다
- 아키텍처 자체는 GPT-2의 디코더 기반 Transformer를 거의 그대로 따르지만, 일부 레이어에 희소 어텐션(sparse attention) 패턴을 도입한 점이 특징.
- 구체적으로 GPT-3에서는 Transformer 레이어를 쌓을 때 교대로 일반 어텐션 레이어와 국소적 희소 어텐션 레이어를 배치하였는데, 이는 OpenAI의 Sparse Transformer 연구를 응용하여 어텐션 연산의 일부만 활성화하는 기법.
예를 들어 한 레이어에서는 모든 토큰 간 완전 연결 어텐션을 하고, 다음 레이어에서는 각 토큰이 인접한 일부 토큰(국소 윈도우)에 대해서만 어텐션하도록 하여 계산량을 줄이는 방식. 이렇게 희소 패턴을 섞으면 모델 파라미터 수는 그대로인 채 메모리와 연산 비용을 절약 가능
- 구체적으로 GPT-3에서는 Transformer 레이어를 쌓을 때 교대로 일반 어텐션 레이어와 국소적 희소 어텐션 레이어를 배치하였는데, 이는 OpenAI의 Sparse Transformer 연구를 응용하여 어텐션 연산의 일부만 활성화하는 기법.
구조적 구성:
- hidden size 12,288, 어텐션 헤드 96개, 총 96개 레이어로 이루어진 거대한 Transformer이며, GPT-2에서 사용된 수정된 파라미터 초기화 기법과 Pre-LN 등 안정화 기법도 동일하게 적용
Few-Shot Learning과 작업 적응:
- GPT-3 논문의 핵심은 파인튜닝을 하지 않고도 소량의 예시만으로 새로운 작업을 푸는 Few-Shot Learning 능력을 대규모 언어모델이 획득함을 보여줌
-
GPT-3에서는 모델의 파라미터를 고정한 채, 질의에 대한 몇 개의 예시(Q-A 쌍 등)를 연달아 프롬프트로 제공하고 이어서 새로운 질의를 주면, 모델이 문맥에 주어진 예시들을 토대로 마치 학습된 것처럼 적절한 응답을 생성.
-
one-shot 설정에서는 한 개의 예시만, few-shot 설정에서는 여러 개(K=10~100) 예시를 제공하며, (zero-shot)은 예시 없이 작업 지시 문장만 주어지는 경우로 정의.
- K개의 예시를 포함한 프롬프트의 총 길이는 모델의 컨텍스트 윈도우(GPT-3의 경우 2048 토큰) 내로 제한되므로, GPT-3에서는 최대 수십 개의 예시까지 활용 가능. 이러한 Few-shot 학습 동안 모델 가중치는 업데이트되지 않고, 주어진 맥락 내에서만 학습이 이루어짐.
- 파인튜닝은 대량의 레이블된 데이터로 모델 가중치를 업데이트하여 작업에 최적화하는 반면, GPT-3 Few-shot은 거대한 사전훈련된 모델 하나가 내부적 일반화로 여러 작업을 바로 수행한다는 차이가 있다.
모델이 메타러너(meta-learner)로서 느린 외부 학습(사전훈련)과는 별개로 빠른 “맥락 속 학습”을 수행한다
요약하면
- GPT-3는 파인튜닝 없이도 충분히 큰 모델에서는 소량 예시만으로 새로운 작업에 적응 가능한지를 입증.
학습 최적화 및 데이터 처리:
- GPT-3의 175B 모델을 학습하기 위해 OpenAI는 수천 개의 GPU로 구성된 클러스터에서 분산 학습을 수행.
- 모델 병렬화와 데이터 병렬화를 모두 활용했는데, 모델의 깊이 방향으로 레이어들을 분할하고 너비 방향으로도 행렬 연산을 쪼개 여러 GPU에 할당함으로써 노드 간 통신을 최소화.
- 예를 들어 한 GPU가 Transformer의 일부 층을 담당하고 다음 GPU가 다음 몇 개 층을 담당하는 파이프라인 병렬화를 적용함과 동시에, 같은 층의 거대한 매트릭스 곱셈 연산은 여러 GPU로 나눠 수행하는 텐서 병렬화 기법을 쓴 것
- 또한 연산 속도를 높이고 메모리 사용을 줄이기 위해 혼합 정밀도(FP16 연산 등)를 사용하고, 배치 크기와 학습률 스케줄을 모델 크기에 맞게 조절.
- 포함된 추가 데이터로는 GPT-2에 사용했던 WebText의 확장 버전, 인터넷에서 수집한 두 종류의 거대 전자서적 코퍼스, 그리고 영어 위키피디아 등
- 최종적으로 GPT-3은 약 3,00억 토큰에 이르는 방대한 텍스트로 학습되었는데, 이는 GPT-2 학습량(약 100억 토큰)보다 30배 이상 많은 규모.